Clouddriver Caching Agents in Spinnaker
How Spinnaker discovers and caches infrastructure elements
Clouddriver is the Spinnaker service responsible for discovering and caching cloud provider infrastructure, such as AWS EC2 instances, Kubernetes pods, and Docker images. Clouddriver has a caching agent scheduler that runs caching agents for providers in separate threads at scheduled intervals. These agents query the infrastructure, index the data, and save the results in a cache store, which is usually a Redis or a SQL datastore.
The caching agent
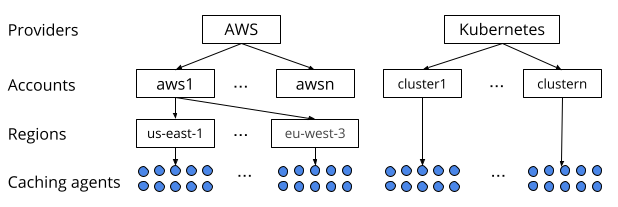
Clouddriver providers and caching agents architecture
Caching agents query your cloud infrastructure for resources and store the results in a cache store. Each provider has its own set of caching agents that Spinnaker instantiates per account and, sometimes, per region. Each caching agent specializes in one type of resource, such as server groups, load balancers, security groups, or instances.
The number of caching agents varies greatly between providers and Clouddriver configurations. For example, AWS might have between 16 and 20 agents per region performing tasks such as caching the status of IAM roles, instances, and VPCs. AWS might also have some agents operating globally for tasks like cleaning up detached instances. Kubernetes, on the other hand, might have a few agents per cluster, caching things like custom resources and Kubernetes manifests.
The cache store
The cache store is where Clouddriver stores cloud resources. You can use different types:
- Redis - the default and most popular implementation.
- SQL - recommended store. For how to configure Clouddriver to use SQL, see the Configure Clouddriver to use a SQL Database.
- an in-memory cache that is not used for actual Spinnaker deployments.
With the exception of the in-memory store, these stores work across multiple Clouddriver instances.
One or more instances of Clouddriver update this single cache store.
The caching agent scheduler
The caching agent scheduler runs caching agents at regular intervals across all Clouddriver instances. There are multiple types of schedulers:
- the Redis-backed scheduler that locks agents by reading/writing a key to Redis.
- the Redis-backed sort scheduler that locks agents by reading/writing a key to Redis and manages the order of agents being executed.
- the SQL-backed scheduler that locks agents by inserting a row in a table with a unique constraint - not very efficient, prefer other schedulers.
- the default scheduler that doesn’t lock. Don’t use this if you expect to run more than one Clouddriver instance.
The cache store does not dictate the type of agent scheduler. For instance, you could use the SQL cache store along with the Redis-backed scheduler.
If you read the Clouddriver source code, you see references to cats (Cache All The Stuff), which is the framework that manages agent scheduler, agents, and cache store.
How the cache store, scheduler, and agent work together
When Clouddriver starts, it inspects its configuration and instantiates the cache store and the agent scheduler. For each provider enabled, Clouddriver instantiates agents per account and region and then adds them to the scheduler.
When the scheduler runs, Clouddriver contacts agents not currently running on its own instance. The scheduler attempts to obtain a lock on the agent type/account/region to ensure that only a single Clouddriver instance caches a given resource at any given time. If Clouddriver obtains a lock, the agent is then run in a separate thread. When the agent finishes, Clouddriver updates the lock Time To Live (TTL) to match the next desired execution time.
On-demand caching agents
Most cloud mutating operations are not synchronous. For example, when Clouddriver sends a request to AWS to launch a new EC2 instance, the API call returns successfully but the EC2 instance takes a while to be ready. This is when Spinnaker uses on-demand caching agents.
On-demand caching agents are, as their name implies, created on demand by the client (Orca) in tasks such as Force Cache Refresh or Wait for Up Instances. They are used to ensure cache freshness and keep things up to date when a resource is created or effectively deleted.
When using a cache store like Redis that works across multiple Clouddriver instances, Clouddriver waits for the next regular caching agent of the same type to run before declaring the cache consistent. It gives the cache store one more chance to replicate its state to other replicas in the case of Redis.
Next steps
- Configure Clouddriver Caching Agents in Spinnaker
- If you are using Kubernetes and would like to use a different method for cataloging your Kubernetes infrastructure, see the Armory Agent for Kubernetes. It’s a lightweight, scalable service that monitors your Kubernetes infrastructure and streams changes back to Clouddriver.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.